„Things not strings“. Mit dieser Aussage macht Google klar, wo die Zukunft der Suchmaschine hingehen soll. Google will nicht nur einzelne Keywords bzw. Zeichenketten verstehen, sondern die Inhalte welche dahinter stehen interpretieren können. Google will auf dem Weg von der Such- zur Antwortmaschine Texte, Inhalte und Zusammenhänge verstehen können und dem User auch ohne die „exakt richtigen“ Keywords in der Suchanfrage das „ideale“ und auf seine Bedürfnisse / Suchintention exakt passende Suchergebnis ausspielen. Wenn man dem Vortrag von Marcus Tandler auf der SMX 2014 in München Glauben schenken darf, dann hat Google jetzt schon Grundschulniveau erreicht wenn es um das Lesen und vor allem das Verstehen von Texten geht. Dieses Verstehen von Texten und nicht nur „Abscannen“ von Zeichenfolgen wird vor allem auch unter dem Aspekt der zunehmenden Bedeutung von Voice Search und Conversational Search wichtiger. Um dieses Verstehen von Suchanfragen zu beschleunigen wirft Google zahlreiche Patente, wie z.B. das Related Entities-Patent zur Interpretation der Beziehungen zwischen Entitäten in den Ring. Zudem gibt es eben auch die Möglichkeiten zur Auszeichnung von Daten im Quelltext um Google dabei zu helfen, dass die Suchmaschine versteht was sich hinter einem Begriff genau verbirgt – ob es sich bspw. bei Catbird Seat um eine Person, ein Produkt oder ein Unternehmen handelt.
So ist der Begriff Schema.org sicherlich schon vielen SEOs und Online-Marketern begegnet. In der Praxis wird diese Auszeichnungssprache jedoch trotz langer Existenz oftmals noch stiefmütterlich behandelt und es ist noch einigen Leuten unklar, was sich denn genau hinter Schema.org verbirgt. Dieser Artikel soll Licht ins Dunkel bringen, aufzeigen was Schema.org ist, wie man es einsetzt, welche nützlichen Tools es in diesem Bereich gibt, warum es ausgerechnet jetzt wichtig wird für die Suchmaschinenoptimierung ist und warum zur Hölle wir Google damit beim Lesen lernen helfen. (Hinweis: Da dieser Artikel einen ausführlichen Leitfaden darstellen soll, ist er doch etwas umfangreicher. Schnapp dir also ein kühles Bier, mach es dir bequem und dann viel Spaß beim Lesen).
1.Was ist schema.org?
Was ist Schema.org? Schema.org ist ein Auszeichnungsvokabular (keine Sprache wie oftmals behauptet), das offiziell am 2. Juni 2011 von Google, Bing und Yahoo initiiert wurde. Mittlerweile unterstützt aber auch Yandex offiziell dieses Tagging-System. Mit Schema.org lassen sich kurz gesagt Inhalte, welche auf einer Website zu finden sind, strukturiert auszeichnen, so dass die Suchmaschinen leichter verstehen können, was sich hinter diesen Inhalten konkret verbirgt und wie sie mit anderen Inhalten im Web in Verbindung stehen. Auszeichnungen signalisieren z.B. Google, ob es sich bei einem bestimmten Objekt um ein Produkt, eine Person, ein Rezept etc. handelt. Im Grunde ist Schema.org vergleichbar mit dem Open Graph Protocol von Facebook, wobei Schema.org hinsichtlich Auszeichnungstypen deutlich ausführlicher und umfangreicher ist als das Open Graph Protocol. In der Praxis empfiehlt es sich sowohl Schema.org (hierauf fokussieren sich die großen Suchmaschinen) als auch das Open Graph Protocol (Fokus von Facebook) zu nutzen, um diesen Systemen die Interpretation der Webseiten-Inhalte zu erleichtern.
Zur Auszeichnung von Webinhalten gibt es übrigens verschiedene Möglichkeiten:
- Microdata
- Microformats
- RDFa (Ressource Description Framework in Attributes)
Schema.org ist dabei ein Auszeichnungsvokabular bzw. –system innerhalb der Microdata-Sprache. Bevor es Schema.org gab, unterstützten die Suchmaschinen dabei alle 3 Markup-Sprachen für strukturierte Daten um bspw. Rich Snippets darzustellen. Seit der Schema.org-Initiative wird allerdings nur noch Microdata von Google unterstützt (Punkt 3: Why microdata? Why not RDFa or microformats?).
Nun haben wir uns angesehen, was Schema.org überhaupt ist und wissen, dass es eine Auszeichnungssprache ist, welche im Quellcode der Seite hinterlegt wird, somit für den Nutzer im eigentlichen Inhalt nicht sichtbar, aber für Google sehr einfach zu lesen ist und dabei hilft, Inhalte zu verstehen.
Jetzt stellt sich uns auch schon die nächste Frage…
2.Warum wird schema.org so wichtig?
Wenn man schnell vorgreifen will, kann man diese Frage knapp mit zwei bekannten Begriffen beantworten: „Rich Snippets“ und „Hummingbird“.
Zum einen werden ausgezeichnete Daten seit 2009 teils in den SERPs in Form von Rich Snippets dargestellt. Sucht man bspw. in Google nach „rezept kaiserschmarrn“, so findet man u.a. folgendes Ergebnis:

Dank strukturierter Daten sieht man hier bspw. dass dieses Gericht zur Zubereitung wohl 20Minuten benötigt und man beim Verzehr 596 kcal in sich hinein isst. Des Weiteren bekommen wir dank der Auszeichnung noch ein Bild eines leckeren Kaiserschmarrns angezeigt und sehen, dass dieses Rezept von 15 Usern im Schnitt eine Bewertung von 4,1 Sternen erhalten hat. Abgesehen davon, dass diese Infos durchaus interessant sein können, erhöhen sie doch die Klickattraktivität des Ergebnisses. Vor allem wenn unser Ergebnis als einziges in den SERPs mit einem Bild ausgezeichnet ist.
Ein gutes Beispiel findet man bei der Suche nach Krafttraining (welches nach dem Verzehr von Kaiserschmarrn durchaus sinnvoll sein kann):

Selbst wenn die Seite von Dr. Gumpert in den SERPs nicht an erster Stelle rankt, sticht sie aus allen Ergebnissen doch am meisten heraus. Das Ergebnis dürfte in Folge dessen recht klickattraktiv sein und sich somit die CTR dieses Ergebnisses nach der Einbindung des Autorenbildes stark erhöhen. Auch wenn die Einbindung von Schema.org laut Matt Cutts keine direkten Auswirkungen auf das Ranking hat, macht die Auszeichnung der Daten also durchaus Sinn. Denn zumindest die positiven Nutzersignale in Form einer erhöhten CTR könnten als Indikator für hohe Qualität und Relevanz zu Steigerungen in den Rankings beitragen. Zudem kann eine Steigerung der CTR natürlich auch in einem Trafficzuwachs in der organischen Suche münden. Diverse Case Studies aus den USA belegen hier bei einigen Firmen einen Trafficzuwachs von bis zu 30% nach der Auszeichnung der Online-Inhalte mittels Markups.
Doch der viel wichtigere Grund warum die Einbindung von Schema.org Sinn macht ist die zunehmende Bedeutung der semantischen Suche und des semantischen Web. Google (und sicherlich auch andere Suchmaschinen) wollen wie bereits angesprochen, Texte nicht nur maschinell auslesen können sondern diese auch interpretieren und die Zusammenhänge zwischen verschiedenen Objekten und Entitäten im Web erkennen. Die ersten Indizien hierfür sind das Hummingbird-Update als auch die Einführung des Knowledge Graphes. Das Hummingbird-Update, welches im 3. Quartal 2013 ausgerollt wurde, ist einer der größten Algorithmus-Änderungen der letzten Jahre – wenn nicht sogar die größte. Hierbei handelt es sich um kein penalty-basiertes Update, sondern eben um eine Algorithmus-Änderung von der laut Google ca. 90% aller Suchanfragen betroffen sind. Dabei sind nicht die Rankings einzelner Keywords betroffen, sondern komplexe Suchanfragen sollen so exakt wie möglich beantwortet werden. Bei dieser Beantwortung direkt in den SERPs spielen natürlich auch die Rich Snippets wieder eine gewichtige Rolle, da dem User hier bereits in den Snippets Antworten geliefert werden ohne, dass er auf das eigentliche Suchergebnis klicken muss. Zum anderen hilft schema.org aber nicht nur bei der Erstellung von Rich Snippets, sondern durch viele weitere Auszeichnungsmöglichkeiten, welche aktuell noch nicht direkt in den Ergebnissen angezeigt werden schon bei der Strukturierung und Aufbereitung der Inhalte.
So kann Google die Suchintention des Users besser erfüllen, wenn Inhalte aus dem Index entsprechend aufbereitet sind und Google klar machen, dass diese Inhalte genau die Suchabsicht des Nutzers abdecken (Bsp. Wo gibt es in München den Biergarten mit den meisten Weißbiersorten?) Hierbei muss man bedenken, dass sich zum einen das Suchverhalten dahingehend ändert, dass Suchanfragen immer länger werden und teils auch ganze Fragen in den Suchschlitz gehackt werden. Und zum anderen nehmen natürlich gerade im Mobile-Bereich gesprochene Suchanfragen zu. Übrigens nutzt auch Siri von Apple Schema.org. Viele Köpfe im Online-Marketing fürchten hier natürlich den Umstand, dass Google sich immer mehr zu einer Antwortmaschine a la WolframAlpha entwickeln wird, welche dem Nutzer sofort die passende Antwort ausgibt und ihm das durchklicken der Ergebnisse erspart.
Spätestens wenn Schema.org doch als Ranking-Faktor bekannt gegeben wird, werden sich auch die letzten SEOs darauf stürzen und ihre Inhalte mit Schema.org auszeichnen. Warum sollte man Google also nicht gleich dabei helfen das „Lesen“ (bzw. besser gesagt das Verstehen) von Inhalten zu erlernen? Schließlich ist es seit Anbeginn das erklärte Ziel von Google die besten Ergebnisse auszuliefern. Warum sollte Google es also nicht belohnen, wenn man seine Seite mit Schema.org aufwertet (vorausgesetzt die Seite bietet gute Inhalte)? Auch hat sich in der Vergangenheit schon öfter gezeigt, dass es möglich war Google-konform zu arbeiten, auch wenn es auf den ersten Blick keinen direkten Vorteil für den Webmaster oder den SEO bringt, sondern man in erster Linie erst einmal „nur“ Google die Arbeit erleichtert. Dies ist oftmals in positive Veränderungen beim Ranking gemündet. Beispiele hierfür sind das Bereitstellen einer XML-Sitemap oder das Einbinden von Canonicals.
3.Wie sieht es aktuell mit der schema.org-Verbreitung aus?
Betrachtet man Schema.org in Google Trends , lässt sich schnelle erkennen, dass das Thema zunehmend ins Bewusstsein der Online-Marketer vordringt (Der Peak in 2011 geht natürlich mit dem Launch und der Erklärung der drei Suchmaschinen einher).
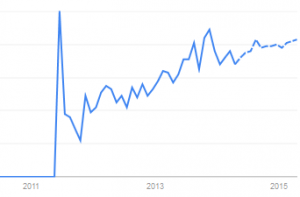
Sieht man sich das regionale Interesse in Google Trends an, fällt auf, dass sich das Interesse momentan hauptsächlich noch auf USA, UK und Deutschland beschränkt.

Searchmetrics hat zu diesem Thema 2014 eine Studie herausgebracht, in welcher unter anderem die Nutzung von Schema.org und die Verteilung in den SERPs untersucht wurden. So nutzen in Deutschland nur ca. 0,41% aller URLs aus dem Searchmetrics Pool aktuell Schema.org. Searchmetrics stellte – wenig verwunderlich – fest, dass bei großen Domains die Nutzung von Schema.org schon häufiger vorkommt als bei kleinen Domains. Bei den Webmastern und Seitenbetreibern ist schema.org also noch nicht wirklich durchgedrungen. Wie sieht es aber in den SERPs aus? Hier ergibt sich Searchmetrics zufolge ein anderes Bild, nach dem nur noch ca. 34% der Keywords kein einziges Rich Snippet in den dazugehörigen SERPs anzeigen. Zusammenfassend lässt sich anhand der Searchmetrics-Studie sagen, dass schema.org von Webmastern aktuell noch in geringem, aber zunehmendem Maße genutzt wird und auf der anderen Seite die Nutzung von schema.org seitens Google in den SERPs zunimmt. Auch weist Searchmetrics korrekterweise daraufhin, dass laut ihrer Untersuchung Seiten mit schema.org-Integration zwar durchschnittlich besser ranken, doch hierbei nicht unbedingt ein kausaler Zusammenhang bestehen muss. Schlecht rankende Seiten sind eben oftmals wenig aktualisiert und häufig auch technisch nicht mehr auf dem neuesten Stand, wohingegen aktuelle Webseiten oftmals nicht nur inhaltlich auf dem neuesten Stand sind sondern auch technisch. Und hierzu gehört eben die Einbindung von schema.org.
Anhand dieser Erkenntnisse und der anfangs aufgeführten Argumente für die Einbindung von schema.org, lässt sich also festhalten, dass schema.org in Zukunft wohl einen immer wichtigeren Faktor im Google Algorithmus und in den SERPs spielen kann und man angesichts der bisherigen Einbindungen durchaus noch die Chance hat, hier als Pionier voranzuschreiten.
4.Was sind die wichtigsten Markups und wie baue ich sie ein?
Zu den wichtigsten Markups gehören zweifelsohne die Auszeichnungen, welche laut Google auch in den Rich Snippets dargestellt werden. Hierzu zählen folgende Rich Snippet Typen:
- Breadcrumbs
- Events
- Musik
- Organisationen
- Personen
- Produkte
- Rezepte
- Review-Bewertungen
- Software-Anwendungen
- Videos
Schema.org hilft Personen (bspw. dabei) die Person als solche zu kennzeichnen und indes mit Merkmalen wie Geschlecht oder dem Geburtsdatum der Person zu verknüpfen. So merkt Google bspw. nicht nur, dass die Zeichenfolge „Arnold Schwarzenegger“ eine Person darstellen soll, sondern dass diese Entität auch noch männlich ist, am 30. Juli 1947 in Österreich geboren wurde mit Maria Shriver verheiratet war und als Job mal den Posten des Gouverneurs von Kalifornien inne hatte. Dabei sollte aber noch einmal betont werden, dass Google bei weitem nicht alle Auszeichnungen in den SERPs anzeigt und man bspw. in den Google Webmaster Tools mithilfe des Google Data Highlighters auch nur einige wenige Elementtypen auszeichnen kann.
Die schier endlose Anzahl an Schema-Typen welche man mittels schema.org auszeichnen kann und ihre Hierarchien findet sich hier: http://schema.org/docs/full.html
Hier macht es durchaus Sinn sich einmal durch die Typen durchzuarbeiten und die für die eigene Seite respektive das eigene Geschäft wichtigsten Schemas herauszupicken. Sieht man sich dann z.B. den Typ „Movie“ an, gibt es hierfür wieder eine eigene Seite mit welchen Properties (Eigenschaften) sich der Typ „Movie“ ausstatten lässt, wie „actor“, „director“, „producer“ uvm.
Wollen wir uns nun am Beispiel meines Lieblingsfilmes Pulp Fiction einmal anschauen, wie man für dieses Beispiel eine Auszeichnung im Quellcode vornimmt.
Grundsätzlich sind die Schemas wie bereits angesprochen in Typen (oft auch als Scopes bezeichnet) und dazugehörige Properties unterteilt. Die Schema-Typen sind dabei in Hierarchien aufgeteilt.
In unserem Beispiel – wir wollen einen Kinofilm auszeichnen – wäre die Hierarchie wie folgt:
Thing > Creative Work > Movie
Sehen wir uns den Type Movie nun an und wir finden die passenden Properties: actor, director, duration, musciBy, producer, productionCompany, trailer.

Hier kommt nun der Clou: Sieht man sich das Beispiel Actor an, fällt auf, dass Actor nicht nur eine Property von Movie ist, sondern auch von Person. Hierdurch werden Verbindungen zwischen verschiedenen Typen geschaffen. Hinterlegt man bei Pulp Fiction als Property actor bspw. John Travolta versteht Google, dass John Travolta ein Schauspieler im Film Pulp Fiction ist. Doch wer oder was ist John Travolta. Dieses Rätsel löst sich für Google dadurch, dass John Travolta ja auch noch als Typ Person ausgezeichnet wird. Für den Typ Person gibt es dabei noch deutlich mehr Properties wie zum Beispiel das Geburtsdatum (Property: birthDate). Wenn man also John Travolta entsprechend auszeichnet, versteht Google auch, dass es sich um eine Person handelt welche am 18. Februar 1954 geboren wurde. Man sieht also wo die Reise hingeht…
 Hätte man im Google Suchschlitz früher eingegeben „Wie heißt der Schauspieler aus Pulp Fiction der am 18. Februar 1954 geboren wurde?“, hätte man Ergebnisseiten ausgespielt bekommen, welche in etwa diese Frage auf ihrer Seite formuliert hätten. In Zukunft werden bei derartigen Suchanfragen aber Seiten ausgespielt, welche diese Fragen beantworten bzw. bei derart banalen Fragen die Antwort direkt in den Google Ergebnissen ausgespielt.
Hätte man im Google Suchschlitz früher eingegeben „Wie heißt der Schauspieler aus Pulp Fiction der am 18. Februar 1954 geboren wurde?“, hätte man Ergebnisseiten ausgespielt bekommen, welche in etwa diese Frage auf ihrer Seite formuliert hätten. In Zukunft werden bei derartigen Suchanfragen aber Seiten ausgespielt, welche diese Fragen beantworten bzw. bei derart banalen Fragen die Antwort direkt in den Google Ergebnissen ausgespielt.
Nun aber zurück zum praktischen Teil. Dem Einbauen von schema.org für Pulp Fiction in den Quellcode.
Zwei wichtige Elemente sind hierbei <div>, ein sogenanntes Block-Element welches Bereiche des HTML-Codes gruppiert bzw. definiert und <span>, ein Inline-Element welches innerhalb eines Bereiches bspw. einen bestimmten Teil des Textes formatiert (z.B. Fettdruck).
Innerhalb unsers <div>s finden wir nun Infos zum Film als HTML:

Nun zeichnen wir Pulp Fiction als Movie aus. Hierzu müssen wir festlegen, dass wir das Objekt auszeichnen wollen, welches sich in unserem <div> befindet. Dazu ergänzen wir hier das Attribut itemscope: <div itemscope>
Anschließend legen wir fest um welchen Schema-Typen es sich handelt. Dies geschieht dadurch, indem wir als itemtype die entsprechende URL festlegen: <div itemscope itemtype=http://schema.org/Movie>
Anschließend können wir die Eigenschaften (Properties) des Movies festlegen, also Name und Schauspieler. Hierzu müssen wir die entsprechenden Eigenschaften mit einem itemprop-Attribut versehen um Google und den anderen Suchmaschinen zu signalisieren, welches die Eigenschaften in unserem Dokument sind. Da die Schauspielernamen in unserem Fall kein eigenes Element sind, sondern im Fließtext „Schauspieler: John Travolta“ bzw. „Schauspieler: Uma Thurman“ stehen müssen wir das itemprop-Attribut vor den Schauspielernamen noch um ein <span> ergänzen, um zu speziell diesen Teil im Fließtext auszuzeichnen. Damit hätten wir es auch schon geschafft.

Die Profi-Coder mögen es mir verzeihen, dass ich ein derart banales Beispiel genommen habe – aber zum einen bin ich selbst absolut kein Profi-Coder und zum anderen geht es eher darum das System hinter schema.org zu verstehen und schema.org im Code erkennen zu können.
Keine Angst, natürlich gibt es auch für diese Arbeiten schon zahlreiche schema.org Generatoren und Tester wie z.B. Googles Data Highlighter und das Rich Snippet Testing Tool in den Webmaster Tools oder den Schema Creator bzw. das entsprechende WordPress-Plugin von Raven Tools. Eine ausführliche Vorstellung aller Tools würde aber den Rahmen des Artikels deutlich sprengen… vielleicht schreiben wir hierzu ja mal einen eigenen Artikel.
Ein weiteres praktisches Hilfsmittel für die „eigenhändige“ Implementierung von schema.org im HTML-Code liefert das Cheat-Sheet von Ann Smarty.
Übrigens: Wer nun auf die Idee kommen sollte, dass er hier ja z.B. Ratings manipulieren könnte sei vorgewarnt. Google hat hier bereits ein eigenes Tool eingerichtet mit welchem man Spam in diesem Bereich melden kann und offiziell gab es auch schon die erste Abstrafung bzgl. Rich Snippet Spam.
5.Fazit
Auch wenn es einige Kritiker geben mag, welche noch gegen schema.org wettern, so bin ich der Meinung dass es in Zukunft doch sehr sinnvoll sein wird und Vorteile bringen wird, wenn man seine Inhalte mit schema.org auszeichnet. Somit hilft man nicht nur Google beim Lesen lernen sondern dürfte wohl bald auch einen Vorteil in der Auffindbarkeit gegenüber Seiten ohne Auszeichnung haben.
Man darf dabei nicht nur an Google denken. Wie Karl Kratz regelmäßig proklamiert wird Google vielleicht nicht ewig die einzige Suchmaschine bzw. das einzige Suchmedium sein. Man denke dabei nur an die Themen Voice Search und Conversational Search. Vor diesem Hintergrund kann es sicherlich nicht schaden, seine Daten für die verschiedenen Maschinen / Medien so perfekt wie möglich aufzubereiten. Wer hier fleißig ist, wird mit Sicherheit belohnt. Und wie die Searchmetrics-Studie zeigt, hat man aktuell noch die Möglichkeit, hier zu den Pionieren und Vorreitern zu gehören. Und diese bekommen ja bekanntlich meist das größte Stück vom Kuchen ab.
Wer also eine neue Seite startet bzw. seine bestehende Seite relauncht sollte die Auszeichnung der Inhalte mittels schema.org auf jeden Fall in Erwägung ziehen. Alle anderen sollten sich die wichtigsten Auszeichnungselemente für ihr Business heraussuchen und Schritt für Schritt mit der Auszeichnung beginnen, um für die Zukunft der Suche gewappnet zu sein.
Bilderquelle “Pulp Fiction”:©Flickr – Abraxas3d / CC BY-NC 2.0
[HINWEIS: diesen Blogbeitrag hatte ich ursprünglich auf dem früheren Catbird Seat Blog publiziert]


















 Nachdem ich die letzten Jahre regelmäßig die meisten großen SEO-Konferenzen im deutschsprachigen Raum besucht habe, war mein Plan dieses Jahr mal eine SEO Konferenz im weiter entfernten Ausland zu besuchen.
Nachdem ich die letzten Jahre regelmäßig die meisten großen SEO-Konferenzen im deutschsprachigen Raum besucht habe, war mein Plan dieses Jahr mal eine SEO Konferenz im weiter entfernten Ausland zu besuchen. Neben den Vorträgen konnte diese Konferenz in Thailand natürlich auch mit köstlichem Essen aufwarten. Besonders frisches Obst gab es hier in jeder Vortragspause.
Neben den Vorträgen konnte diese Konferenz in Thailand natürlich auch mit köstlichem Essen aufwarten. Besonders frisches Obst gab es hier in jeder Vortragspause. Der zweite Tag startete dann auch schon mit zwei absoluten Highlights an Vorträgen. Im ersten Vortrag zeigte
Der zweite Tag startete dann auch schon mit zwei absoluten Highlights an Vorträgen. Im ersten Vortrag zeigte 

 Wenn es draußen kühler wird, man so langsam den ersten Glühwein und die Plätzchen riecht, dann freuen sich die meisten Leute auf eine ruhige Winterzeit und die SEOs aus dem deutschsprachigen Raum freuen sich über die
Wenn es draußen kühler wird, man so langsam den ersten Glühwein und die Plätzchen riecht, dann freuen sich die meisten Leute auf eine ruhige Winterzeit und die SEOs aus dem deutschsprachigen Raum freuen sich über die  Wer sich die Keynote nachträglich ansehen möchte, findet das entsprechende Video auf
Wer sich die Keynote nachträglich ansehen möchte, findet das entsprechende Video auf  Interessant war auch der anschließende Vortrag von
Interessant war auch der anschließende Vortrag von 
